
「robots.txt」は、検索エンジンのクローラーに対してサイト内の「どのページをクロールしてよいか」または「クロールしないでほしいか」を指示するためのテキストファイルだ。
適切に設定することで、クローラーの挙動をコントロールし、効率的なインデックス登録を促進できる。
一方で、以下のような悩みも多い。
「具体的な設定方法がよくわからない」
「設定を誤って逆効果になりそうで不安」
「そもそも自社サイトでは設定が必要なのか」
そこで本記事では、robots.txtの基本的な役割から実際の設定方法、確認手順、そして設定する際の注意点まで、初心者の方にもわかりやすく解説する。

1. robots.txtとは
robots.txtとは、検索エンジンのクローラー(ロボット)に対して、Webサイト内のどのページやディレクトリをクロールしてよいか、どれをクロールしないでほしいかを指示するためのテキストファイルだ。
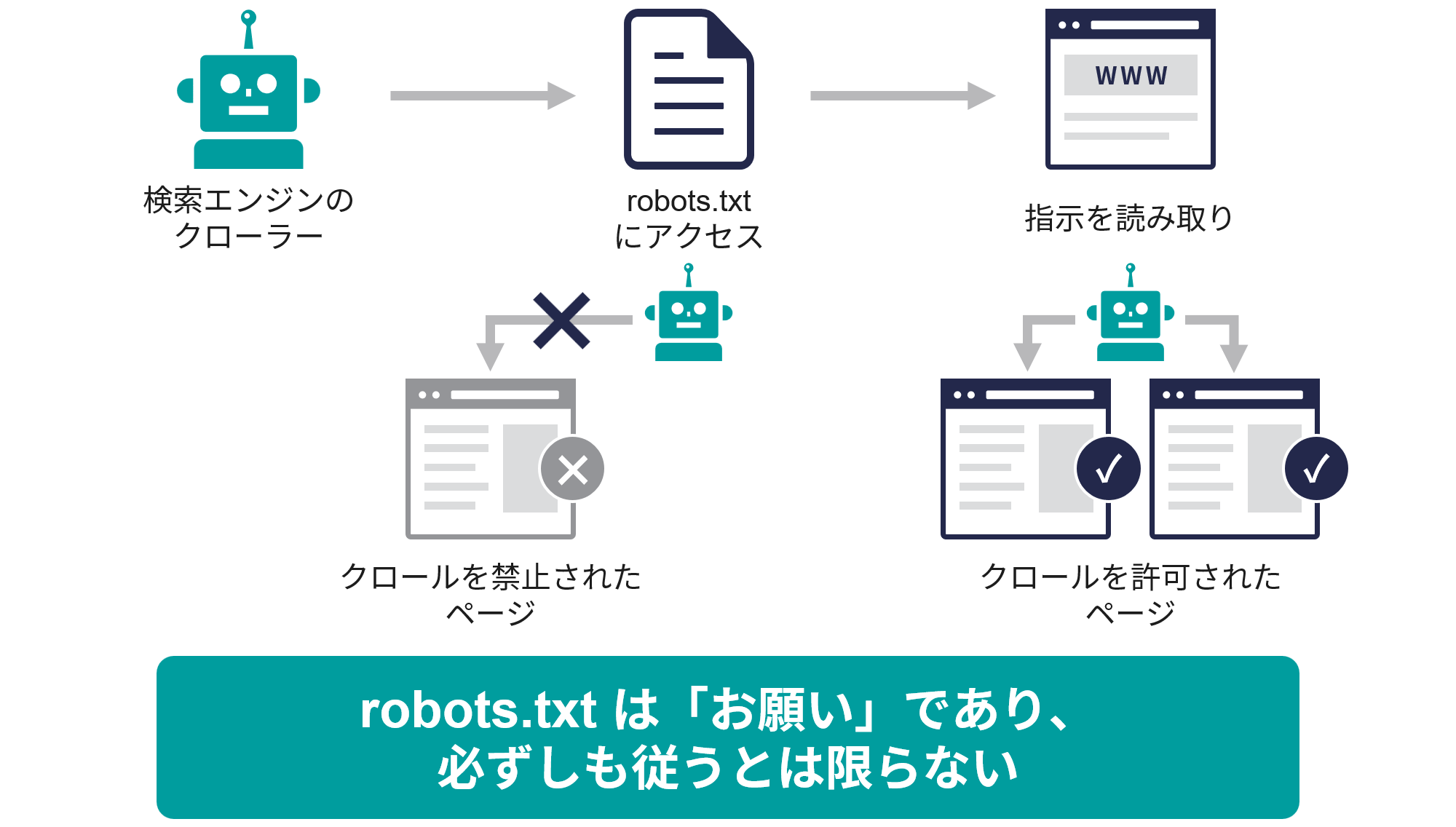
クローラーは、Webサイトにアクセスする際、まずrobots.txtファイルを参照し、その指示に従ってサイト内のページをクロールする。
robots.txtは、Webサイトのルートディレクトリ(最上位階層)に配置されるシンプルなテキストファイルだ。
たとえば「https://example.com/」というサイトであれば「https://example.com/robots.txt」というURLでアクセスできる場所に配置する。
押さえておきたいrobots.txtの主な特徴は以下のとおりだ。
- 検索エンジンのクローラーに対して「訪問のルール」を定義する
- robots.txtはあくまで「お願い」であり、クローラーが必ず従うという保証はない
- robots.txtでは「インデックス」の制御ができない(別途「noindex」タグなどが必要)
- robots.txtは「公開情報」である
robots.txtは、検索エンジンのクローラーにとって「訪問のルール」を定義するものであり、サイト運営者がクローラーの挙動をコントロールする重要なツールだ。
一方で、robots.txtはあくまで「お願い」であり、クローラーがこの指示に必ず従う保証はないことを覚えておこう。
多くの主要な検索エンジンのクローラー(GooglebotやBingbot)はrobots.txtの指示に従うが、クローラーによっては無視されるおそれもある。
また、robots.txtはクロール(サイト訪問)の制御のみを目的としており、インデックス(検索結果への登録)を直接制御するものではない。
つまり、robots.txtでクロールを禁止したページでも、ほかのページからのリンクなどを通じて検索エンジンに認識され、インデックスされる可能性もゼロではない。
よって、インデックスを禁止したい場合、別途「noindex」タグなどの設定が必要だ。
robots.txtファイルは基本的に公開情報となるため、誰でもアクセスして内容を確認できる。
そのため、セキュリティ上の理由でクローラーにアクセスしてほしくないページを指定する際には、その情報も公開されることを念頭に置く必要がある。
2. robots.txtを設定する目的・効果
robots.txtを設定する主な目的は、クローラーのリソースを効率的に使い、重要なコンテンツを逃さずに適切なSEO評価を得ることだ。
具体的には以下が挙げられる。
- サーバーリソースの保護
- クロールバジェットの最適化
- プライベートコンテンツの保護
- メディアファイルのクロール制御
- サイトマップの指定
それぞれみていこう。
2.1.サーバーリソースの保護
検索エンジンのクローラーは、定期的にWebサイトを巡回し、新規コンテンツや更新情報を検出している。
しかし、すべてのページをクロールさせる必要はない。
robots.txtを設定することで、検索結果に表示する必要のないページや、クロールされると負荷がかかるディレクトリへのアクセスを制限できる。
特に、数千ページ以上を有する大規模サイトでは、不要なページへのクロールがサーバー負荷を高め、表示速度の低下を招くケースも少なくない。
robots.txtを適切に活用すれば不要なクロールを抑え、サーバーリソースを効率的に活用できるほか、ユーザー体験の低下を防ぐことにもつながる。
2.2.クロール予算の最適化
検索エンジンは、Webサイトごとにクロールバジェット(Crawl Budget)と呼ばれる巡回のリソースを割り当てている。
クロールバジェットとは、クローラーがサイト内で費やす時間やアクセス回数の上限を指し、無制限にあるものではない。
robots.txtを適切に設定すると、限られたクロールバジェットを検索結果での表示を狙う重要なページへ優先的に割り当てることが可能となる。
特に、ページ数が膨大な大規模サイトでは、重要度の低いページやクロール不要な領域をrobots.txtで制御することで、効率的なクロールの実現とSEO評価の最大化につながるのだ。
なお、Googleは公式にクロールバジェットの考え方とその最適化の必要性について言及している。
参考:大規模なサイト所有者向けのクロールバジェット管理ガイド|Google検索セントラル
2.3.プライベートコンテンツの保護
管理画面や会員専用ページなど、検索結果に表示させたくないプライベートなコンテンツへのクロールを制限できる。
これにより、意図しないページが検索エンジンに巡回されることを防ぎ、機密性の高い情報を保護できる。
ただし上述のとおり、robots.txtはクロールのみを制御するもので、インデックスを完全に防ぐものではない点に注意が必要だ。
参考:robots.txtの概要|Google検索セントラル
noindexタグや認証制限など、別の手法と併用する必要があることを理解しておきたい。
2.4.メディアファイルのクロール制御
画像、動画、PDFなどのメディアファイルは、特に大きなファイルサイズを持つことが多く、クロールに多くのリソースを消費する。
robots.txtを使用して、これらのメディアファイルへのクロールを制御することで、サーバー負荷の軽減とクロール効率の向上が期待できる。
特に、検索結果に表示させる必要のない大量の画像ファイルがあるサイトでは、特定のディレクトリの画像ファイルを除外することが効果的だ。
2.5.サイトマップの指定
robots.txtファイル内に「Sitemap」ディレクティブを記述することで、サイトマップのURLを検索エンジンに伝えられる。
サイトマップはサイト内の構造や重要なページを検索エンジンに知らせるためのファイルであり、クロールやインデックスの効率を高める効果がある。
3. robots.txtとnoindexの違い
robots.txtとnoindexは、どちらもサイトの特定のページを検索結果に表示させないために使用されることがあるが、両者の仕組みと影響は大きく異なる。
以下の表で主な違いをまとめた。
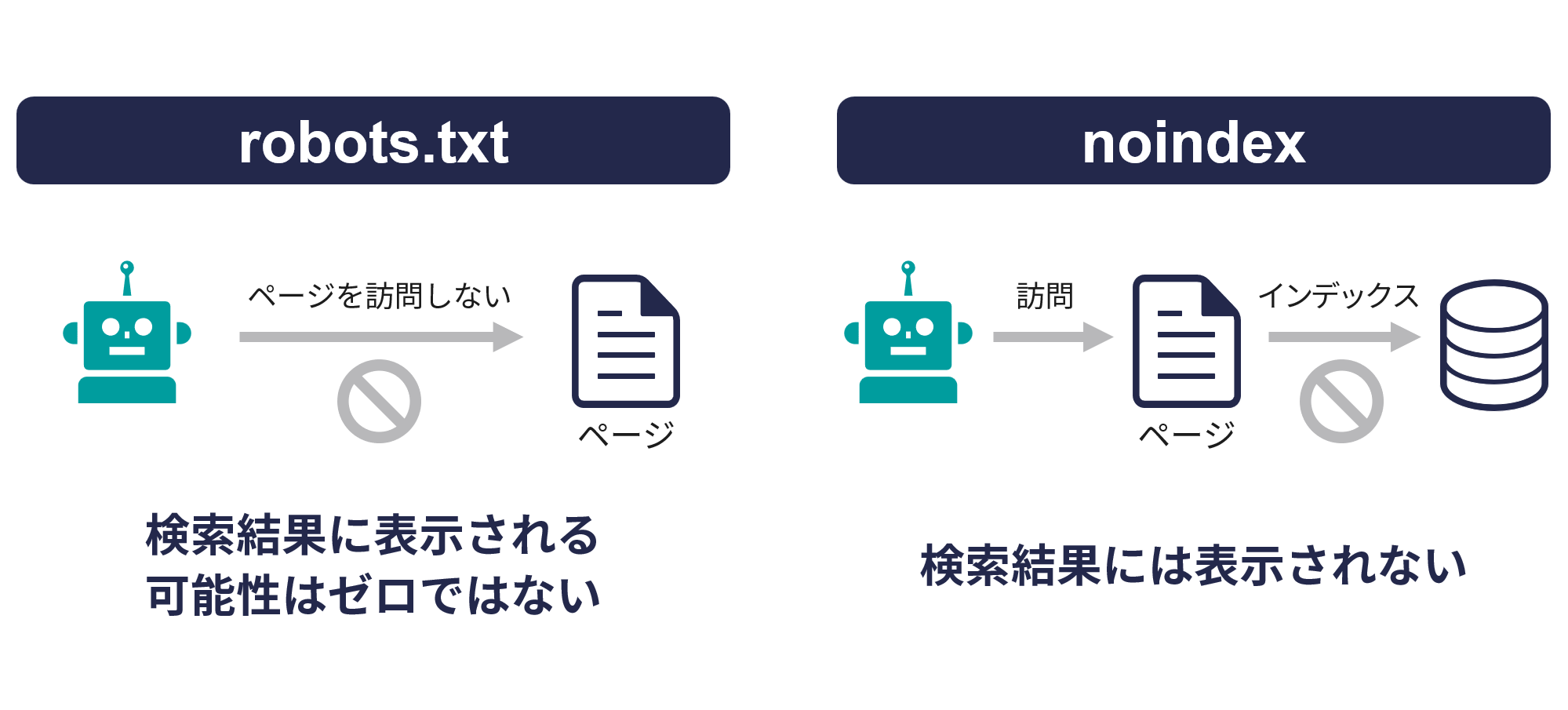
robots.txtはクローラーがサイトを訪問する段階で機能し、noindexはクローラーがページ内容を読み込んだあと、インデックスを作成する段階で機能する。
インデックスされたくないページがある場合、robots.txtによるクロール制限だけでは不十分であり、noindexを併用するのが最も効果的な方法だ。
特に、機密情報や個人情報を含むページは、robots.txtでクロールを禁止するだけではなく、noindexを設定して確実にインデックスされないようにすることが重要だ。
| 項目 | robots.txt | noindex |
| 目的 | クロール(訪問)の制御 | インデックス(データベースへの登録と検索結果への表示)の制御 |
| 設定場所 | サイトのルートディレクトリにてテキストファイルとして配置 | HTMLの<head>内にmetaタグとして記述、またはHTMLレスポンスヘッダーで設定 |
| 影響範囲 | ディレクトリやファイル単位で指定可能 | 個別ページごとに指定 |
| クローラーの動き | 指定したページやディレクトリにはアクセスしない | ページにアクセスしてコンテンツを読み込むが、インデックスには登録しない |
| 検索結果への影響 | クロールされないが他のページからのリンクなどによりページの存在が認識され、検索結果に表示される可能性がある | 検索結果には表示されない |
| 設定の確実性 | 「お願い」レベルであり、全てのクローラーが従うとは限らない | より確実にインデックスを防止できる |
4. robots.txtが必要なケース
robots.txtはすべてのWebサイトに必須ではない。
しかし、以下のようなケースでは特に有効活用できる可能性がある。
- 中〜大規模サイト
- メディアファイルを検索結果に表示させたくない場合
- クロールに問題が生じている場合
- プライバシーやセキュリティが懸念される場合
詳しくみていこう。
ケース1.中〜大規模サイト
ページ数が多い中〜大規模サイトでは、クロールバジェットの最適化が重要となる。
robots.txtを使用して優先順位の低いページをクロール対象から除外し、不要なディレクトリへのクロールを制限すると、重要なページのクロール頻度向上につながる。
特に、月間PV数が10万を超えるようなサイト、数千〜数万ページを保有するサイトでは効果を実感しやすいだろう。
ケース2.メディアファイルを検索結果に表示させたくない場合
商品画像や装飾用の画像など、Google画像検索などで表示させる必要のないメディアファイルがある場合、robots.txtの活用が有効だ。
制御したい画像のディレクトリへのクロールを制限することで、クロールバジェットやサーバーリソースの確保につながる。
たとえば、以下のように設定する。
User-agent: Googlebot-Image
Disallow: /images/products/
なお、すでにインデックスされた画像を削除する場合は、robots.txtの設定だけでは不十分だ。
Google Search Consoleの「削除ツール」などの併用が必要となる。
参考:削除ツールとセーフサーチ レポートツール|Search Console ヘルプ
ケース3.クロールに問題が生じている場合
サーバーログを確認し、特定のディレクトリに対するクロールが過剰に行われていることが判明した場合には、robots.txtによるクロール制限が有効だ。
これにより、サーバー負荷の軽減や重要なページへのクロール効率向上が期待できる。
ケース4.プライバシーやセキュリティが懸念される場合
管理画面や会員専用ページなど、一般公開すべきではないコンテンツがある場合、robots.txtでクロールを制限することが有効だ。
ただし上述のとおり、robots.txtはインデックスを制御できないため、noindexなどの他施策との併用が重要だ。
5. robots.txtの設定方法
robots.txtの設定について、難しく感じる方は多いだろう。
一方で、ファイルは非常にシンプルな構造を持ち、主に以下の4つのディレクティブ(命令コード)で構成されている。
| ディレクティブ | 詳細 |
| User-agent | クローラー(ロボット)の種類を指定する。 |
| Disallow | クロールを禁止するディレクトリやファイルを指定する。 |
| Allow | Disallowの例外として、クロールを許可するディレクトリやファイルを指定する。 |
| Sitemap | XMLサイトマップのURLを指定する。 |
それぞれのディレクティブについて詳しくみていこう。
5.1 User-agent
User-agentは、どのクローラー(ロボット)に対して指示を出すかを指定するものだ。
すべてのクローラーに対して同じ指示を出す場合は「*」(アスタリスク)を使用する。
特定のクローラーだけに指示を出したい場合は、そのクローラーの名前を指定する。
記述例
User-agent: *
User-agent: Googlebot
また、主要な検索エンジンのクローラー名は以下のとおりだ。
- Google検索:Googlebot
- Google画像検索:Googlebot-Image
- Microsoft Bing:Bingbot
- Yahoo!:Slurp
- Baidu(中国の検索エンジン):Baidu
5.2 Disallow
Disallowは、クロールを禁止するディレクトリやファイルを指定する。
「/」ではじまり、相対パスで記述する。
記述例
Disallow: /
Disallow: /admin/
Disallow: /secret.html
Disallow: /*?
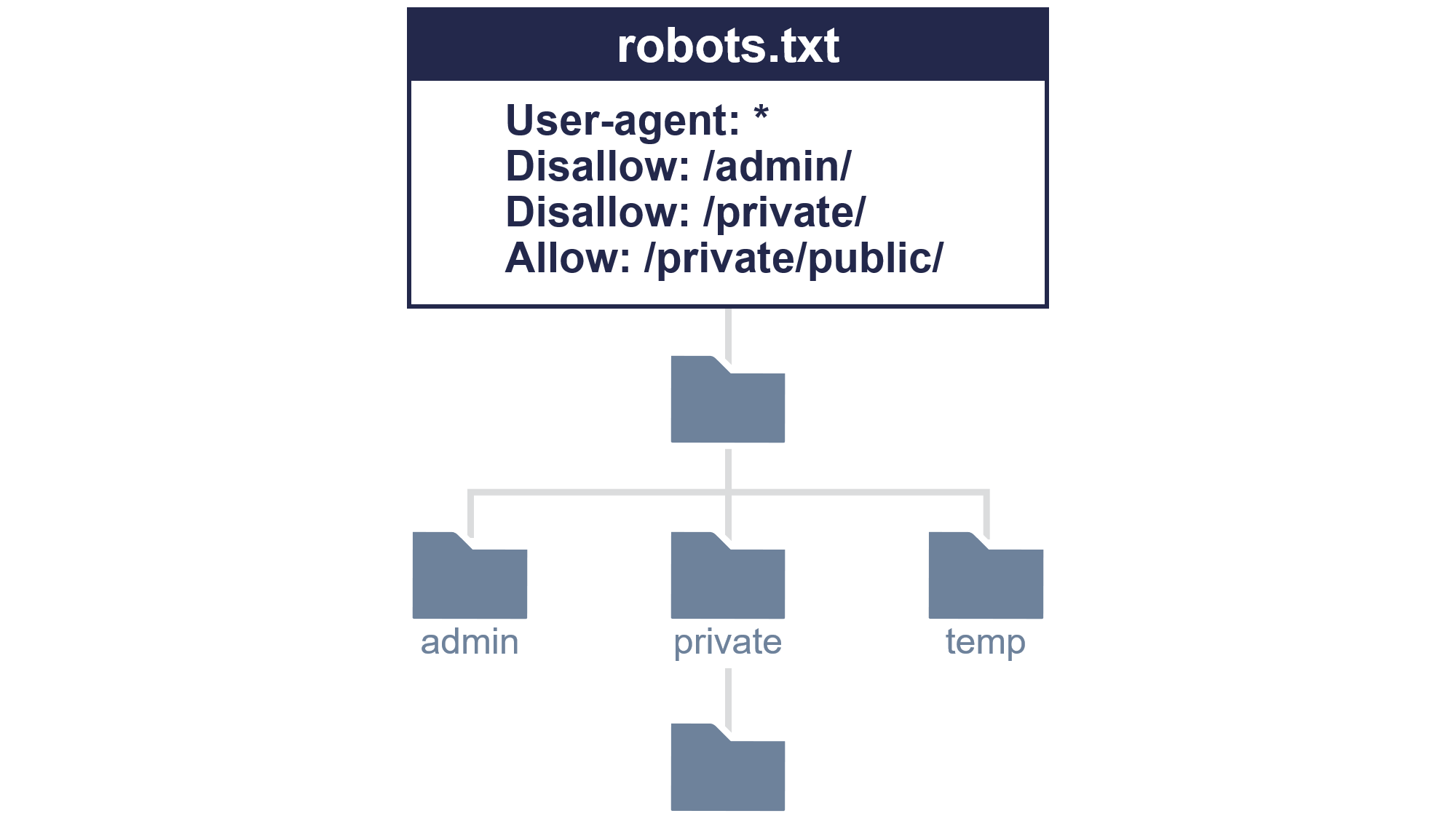
5.3 Allow
Allowは、Disallowの例外として、特定のディレクトリやファイルのクロールを許可するものだ。
主にDisallowと組み合わせて使用する。
記述例
Disallow: /private/
Allow: /private/public/
5.4 Sitemap
Sitemapは、XMLサイトマップのURLを指定するものだ。
サイトマップは検索エンジンにサイト内の重要なページを知らせるためのファイルであり、robots.txtに記述することで検索エンジンに自動的に伝えられる。
Sitemap: https://example.com/sitemap.xml
5.5.robots.txtの設定例とその他ルール
上記を踏まえたrobots.txtの一般的な記述例は以下のとおりだ。
記述例
User-agent: *
Disallow: /admin/
Disallow: /private/
Disallow: /tmp/
Allow: /private/public/
Disallow: /*?
User-agent: Googlebot
Disallow: /no-google/
Sitemap: https://example.com/sitemap.xml
また、robots.txtの記述方法には以下のようなルールがある。
Googleの公式情報としても公開されているため、確認しておこう。
- コメント行の記述
行の先頭に「#」を付けるとコメント行としてみなされ、クローラーは無視する。 - User-agentとそれに続くDisallow/Allowはセットで記述する
User-agent(適用するクローラーの指定)と、それに続くDisallowや Allowの指示は、1つのグループとしてまとめて記述する。
グループごとに適用対象を分ける場合は、空行で区切る。 - パス指定では大文字・小文字が区別されるため正確な記述が必須
たとえば「Disallow: /file.asp」と記述した場合「https://www.example.com/file.asp」へのアクセスは制限されるが「https://www.example.com/FILE.asp」のように大文字が含まれるURLには適用されない。
大文字・小文字を区別したパスの正確な記述が重要。
ただし、User-agentの値(クローラー名)自体は、大文字・小文字を区別しない。 - ワイルドカードなどの特殊文字が使用可能
特定のパターンに一致するURLを指定するために、ワイルドカードなどの特殊文字を使用できる。
たとえば「*」は任意の文字列を表し、「$」はURLの末尾を示す。
これにより、より柔軟なクロール制御が可能となる。
参考:robots.txt の書き方、設定と送信|Google検索セントラル
6.robots.txtファイルの設置手順
robots.txtの設置は以下のステップで行う。
ステップ1.テキストファイルの作成
テキストエディタ(macOSのテキストエディット、VSCode、Atom、Windowsのメモ帳など)を使用して、新しいテキストファイルを作成する。
ステップ2.UTF-8エンコードでの保存
ファイル名をrobots.txtとする。
保存する際には、文字コードを必ずUTF-8(BOMなしを推奨)に指定する。
ステップ3.サーバーへのアップロード
FTPクライアントソフトや、利用しているレンタルサーバーのファイルマネージャー機能などを使用する。
作成・保存したrobots.txtファイルを、ウェブサイトのルートディレクトリ(ドキュメントルート、公開フォルダの最上位)にアップロードする。
CMS(コンテンツ管理システム)を使用している場合
WordPressなどのCMSを利用している場合、robots.txtの内容を管理できる専用プラグイン(All in One SEO、Yoast SEOなど)が提供されていることがある。
プラグインによる設定は手軽だが、ほかのプラグインとの競合やサーバー設定の影響により、意図しない動作を引き起こすリスクも存在する。
特に、WordPressでは標準で仮想的なrobots.txtを生成するが、サーバー上に物理的なrobots.txtファイルが存在する場合は、そちらが優先される。
そのため、より確実な管理を行うには、物理ファイルとしてrobots.txtをサーバーのルートディレクトリに直接設置する方法が推奨される。
ステップ4.正しく設置されているかの確認
ファイルをアップロードしたあと、ウェブブラウザのアドレスバーに https://example.com/robots.txt(example.com は自身のドメイン名)と入力してアクセスする。
記述した内容が正しく表示されれば、設置は成功している。
404エラー(Not Found)が表示される場合は、なんらかの原因で設置が失敗していると考えられる。
- 設置場所がルートディレクトリではない
https://example.com/pages/robots.txtのようなサブディレクトリに設置しても認識されない。 - ファイル名が正しくない
「Robots.txt」や「robots.TXT」など、大文字が混在していると認識されない。 - アップロード自体に失敗している
FTPソフトやCMSの操作ミス、通信エラーなどによる。 - ファイルのパーミッション(アクセス権)が適切でない
robots.txtファイルに十分な読み取り権限が設定されていないと、サーバーがアクセスを拒否して404エラーになる場合がある。 - キャッシュやCDNの影響を受けている
直後にアクセスしても古い情報が表示され、実際には設置できていても404が出るケースもある。キャッシュクリアや時間をおいて再確認するとよい。
7. robots.txtテスターでの動作確認方法
Googleが提供する「robots.txtテスター」を使用すると、robots.txtの記述が正しく動作しているかを確認できる。
ステップ1.Google Search Consoleへログイン
Google Search Consoleにログインする。
ステップ2.robots.txtファイルの状況を確認する
- 左側のメニュー下部にある「設定」をクリックする。
- ページ内の「クロール」セクションにある「robots.txt」の項目をクリックする。
- Googleが最後にrobots.txtファイルを取得した日時と、その際のステータス(例:「取得済み」「取得できませんでした(404)」など)を確認できる。
- さらにファイルをクリックすると、Googleが現在認識しているrobots.txtファイルの内容が表示される。
ステップ3:特定のURLがrobots.txtでブロックされているかテストする
特定のURLでrobots.txtが機能しているか(robots. txt)を確認したい場合は、画面上部にある検索バーに該当のURLを入力し、URL検査ツールを使用する。
- 検索バーに確認したいページのURLを入力し、Enterキーを押す。
- 結果が表示されたら「ページのインデックス登録」の状態を確認する。
(まだインデックスされていない場合は「公開URLをテスト」を実行してライブテストの結果を確認する) - 「クロールを許可?」という項目を確認する。
- 「はい」と表示されていれば、robots.txtではブロックされていない。
- 「いいえ: robots.txt によりブロックされました」と表示されている場合、そのURLはrobots.txtによってブロックされている。詳細を開くと、どのルールによってブロックされているかを確認できる。
ステップ4:robots.txtの編集と反映、再確認
robots.txtファイルを編集する必要がある場合、Search Console内では直接編集できない。
自身のウェブサーバー上にあるrobots.txtファイルを直接編集する必要がある。
- 編集が完了したら、変更内容をサーバーにアップロード(保存)する。
Googleが新しいrobots.txtファイルをクロールし、認識するまでには時間がかかる場合がある。 - 変更が反映されたかを確認するには、しばらく時間をおいてからステップ2の方法でGoogleが新しいファイルを取得しているか、ステップ3の方法で意図したとおりにURLのブロック/許可が機能しているかを確認する。
サブディレクトリの場合
サブディレクトリ(例: https://example.com/shop/)には、個別のrobots.txtファイルを設置しない。
特定のサブディレクトリへのアクセスを制御したい場合は、そのドメイン(またはサブドメイン)のルートディレクトリにあるrobots.txtファイル(例: https://example.com/robots.txt)内に記述する。
8. robots.txtの注意点
robots.txtはSEO対策に役立つが、誤った設定や使い方をすると逆効果となるおそれがある。
以下に、robots.txtを設定する際の主な注意点を解説する。
注意点1.クロール禁止とインデックス禁止は別物
robots.txtでクロールを禁止しても、インデックス登録を防げるわけではない。
クロールが禁止されていても、外部リンクなどを通じてURLが検出され、検索結果に表示される可能性がある。
インデックス登録を確実に防ぎたい場合は、以下の方法を使用する必要がある。
- ページの<head>内に<meta name=”robots” content=”noindex”> を設置する
- HTTPレスポンスヘッダーで X-Robots-Tag: noindexを指定する
これらの手法であれば、クローラーがページ内容を取得し、noindexの指示を認識してインデックスからの除外が可能だ。
注意点2.すべてのクローラーがrobots.txtに従うわけではない
robots.txtはあくまで「お願い」であり、その指示に強制力はない。
GooglebotやBingbotなど多くの主要クローラーは従うが、一部のクローラーには無視されるおそれもある。
そのため、機密情報や個人情報を含むページをrobots.txtだけで保護するのは不十分だ。
このようなページでは、パスワード保護や適切なアクセス制限の併用をおすすめする。
注意点3.小規模サイトでは効果が限定的
robots.txtの主な目的は、大規模サイトにおけるクロール効率化だ。
小規模サイトや更新頻度が低いサイトでは、クロールバジェットの最適化による効果が限定的なため、無理に複雑な設定を行う必要はない。
必要最低限の設定か、場合によってはrobots.txt自体を設置しない選択肢をとっても問題ないだろう。
注意点4.過度な制限はSEOに悪影響
重要なページやセクションへのクロールを誤って禁止すると、そのページが検索結果に表示されなくなるおそれがある。
robots.txtの設定は慎重に行い、定期的に見直すことが重要だ。
注意点5.古いrobots.txtが残っている可能性
サイトリニューアルやサーバー移行の際に、古いrobots.txtの設定が残っている場合がある。
これにより、新しいコンテンツのクロールも妨げられるおそれがあるため、サイト変更時にはrobots.txtの見直しも必ず行おう。
注意点6.robots.txtは公開情報
robots.txtは、誰でもブラウザで閲覧可能な公開ファイルだ。
そのため、機密性情報やディレクトリ構造を明かす記述を含めると、セキュリティリスクが高まるおそれがある。
注意点7.ワイルドカードの使用や設定ミスに注意
robots.txtでは「*」や「$」などのワイルドカードを使用することで、特定のパターンに一致するURLを柔軟に指定できる。
しかし、記述方法を誤ると、意図しないページまでクロールをブロックしてしまうリスクがあるため注意が必要だ。
たとえば「Disallow: /」のような記述は、サイト全体へのクロールを禁止する指示となり、クローラーは一切のページを巡回しなくなってしまう。
定期的に設定内容を見直し、Google Search Consoleなどで実際のクロール状況を確認しながら適切な調整を行うことが重要だ。
9. まとめ
本記事では、robots.txtの基本的な役割から設定方法、そして運用上の注意点に至るまでを解説した。
robots.txtとは、検索エンジンのクローラーに対してサイト内の巡回を許可する範囲、あるいは制限する範囲を伝えるためのテキストファイルを指す。
robots.txtの適切に設置・設定により、クロールを効率化し、SEO戦略の一助とすることが可能だ。
ただし、robots.txtはあくまでクロールの制御を目的としており、ページのインデックス登録自体を防ぐものではない。
インデックスから除外したいページには、別途noindexメタタグなどを用いる必要がある。
また、記述ミスは意図せず重要なページへのクロールを拒否してしまうリスクを伴うため、設定後はSearch ConsoleのURL検査ツール(旧robots.txtテスターの代替)などで、意図どおりに機能しているかを確認することが欠かせない。
サイトの特性に応じた適切なrobots.txtの運用は、効果的なWebサイト運営に不可欠な要素といえるだろう。





