
SEOとは「Webサイトやコンテンツを検索エンジンのアルゴリズムに最適化し、検索結果での上位表示を目指す」取り組みだ。
従って、検索エンジン(主にGoogle)が検索順位を決める仕組みを理解していなければ、適切な対策はできない。
近年ではどの企業も「SEO対策に取り組んでいる」かもしれないが、「対策KWを記事に含める」「共起語をたくさん含める」「文字数は競合記事に負けないようにする」などの小手先の対策となっていないだろうか。
労力と時間を無駄にしないためにも、Googleの検索順位が決まる仕組みを理解し、その枠組みに沿った対策を施していきたい。
本記事では、Googleの検索順位決定の仕組みと、そこから推測される上位表示の対策を紹介する。
1.Googleの検索順位決定の仕組み「3つのプロセス」
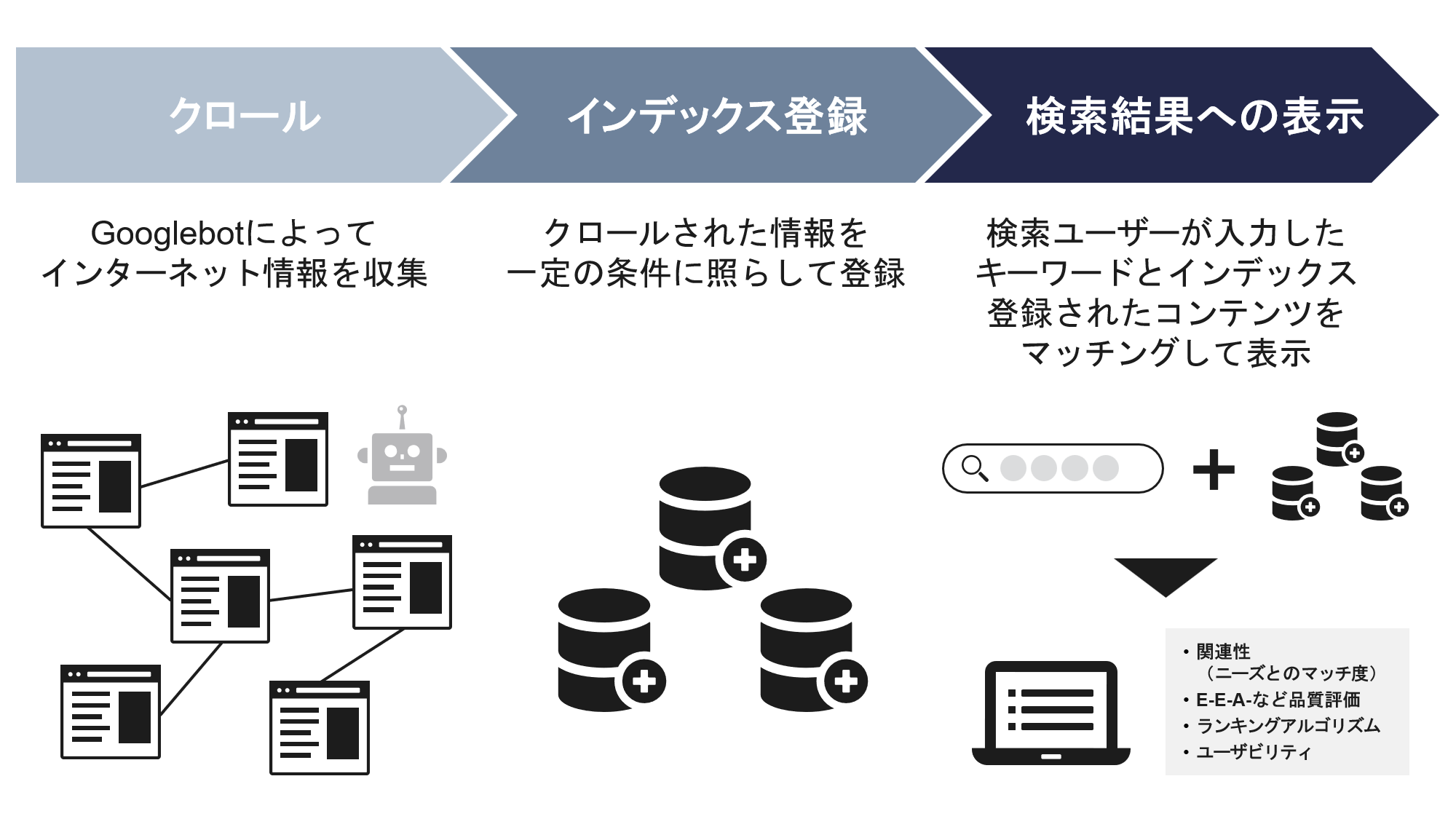
Googleの検索順位は、クロール」「インデックス」「検索結果への表示(順位付け)」の3つの機能によって実現される。
まずはクローラーと呼ばれるロボットがインターネット上にあるコンテンツの情報を収集する。
クローラーが集めた情報は、検索エンジンのデータベースに保存(=インデックス登録)される。
ここまでで、検索結果に表示されるための土台が整う。
そして、ユーザーが検索時に入力したキーワードに応じて「関連性が高い」「品質が高い」など複数の観点から検索順位が決定され、適切なコンテンツが検索結果へ表示されるというわけだ。
それぞれの具体的な動きについて、もう少し詳しく見ていこう。
1.1.クロール(クローラー)
クロールとは、検索エンジンのロボット(bot)がインターネット上のコンテンツを自動収集する行為をさす。
Google検索の対象となるコンテンツは、「Googlebot」と呼ばれるbotによってクロールされる。
具体的には、サイト運営者が作成した「robots.txt」の内容に従ってクロールが行われる。
robots.txtはクローラーに対して、クロール(アクセス)を要求するURLを記載したテキストファイルだ。
つまり、サイト運営者がクロールしてほしいURLをrobots.txtに記載し、クローラーがそのURLを収集する……という流れがクロールの概要だ。
ただし現在は、robots.txtにXMLサイトマップの所在を記載し、XMLサイトマップに記述されたURLを読み込ませる方法が主流だ。
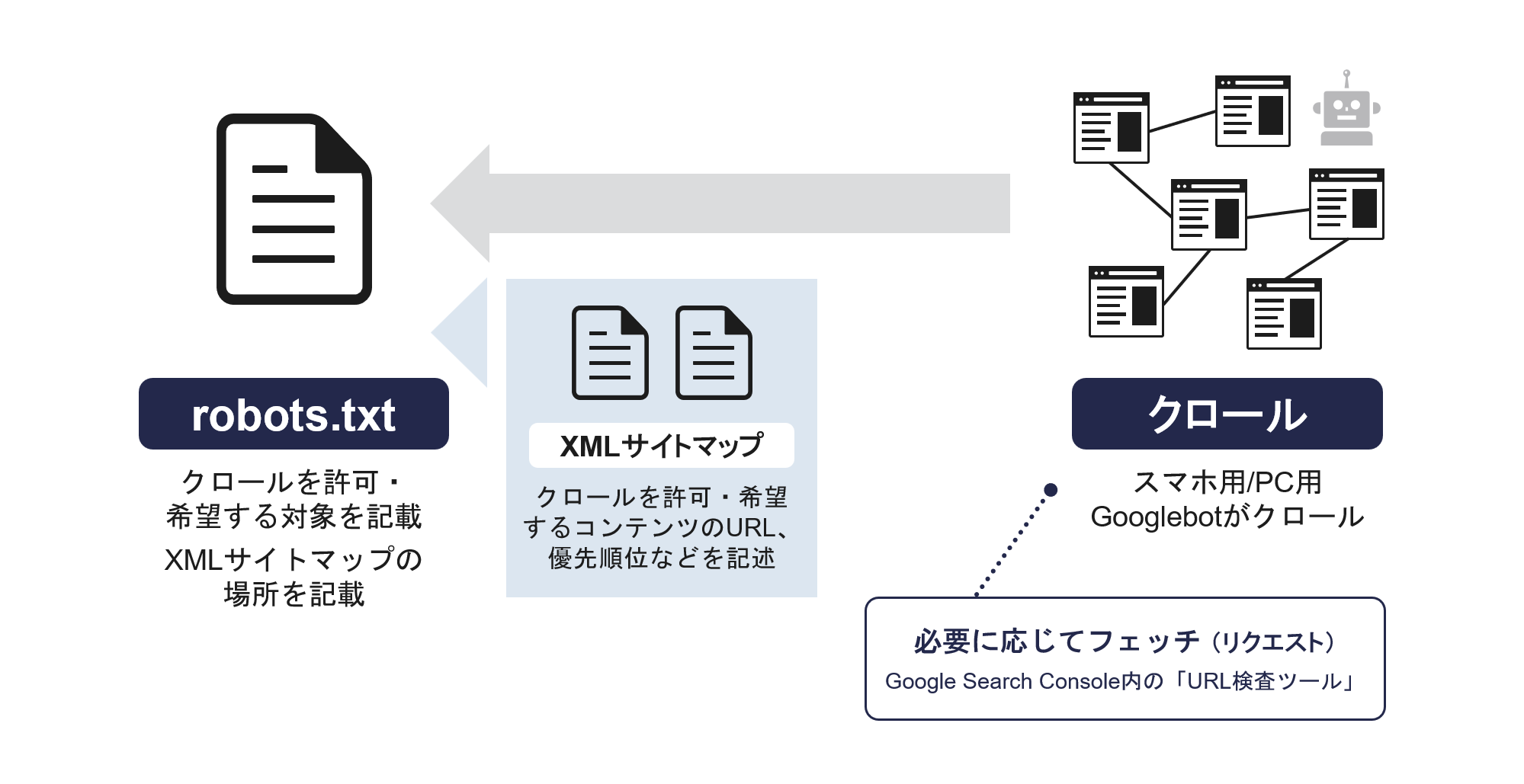
robots.txtへのXMLサイトマップの記述方法は、「sitemap: [サイトマップの絶対URL]」だ。
その他、robots.txtでは、クロールの許可・不許可のための記述ルールが存在する。
ルールについてはGoogle検索セントラルでも公開されているため、参考にしてほしい。
参考:Google による robots.txt の指定の解釈|Google検索セントラル
https://developers.google.com/search/docs/crawling-indexing/robots/robots_txt?hl=ja
ちなみにクローラーが自社サイトを訪問したかどうかは、送信元IPアドレスによって確認できる。
Googlebotの送信元IP範囲は、「googlebot.json」というファイル名で公開されており、この範囲内のIPアドレスからアクセスがあればGooglebotによるクロールが行われたと判断できる。
GooglebotのIPアドレス(JSONファイル):https://developers.google.com/search/apis/ipranges/googlebot.json
参考:クローラーがGooglebotなどのGoogleクローラーであることを確認する|Google検索セントラル
https://developers.google.com/search/docs/crawling-indexing/verifying-googlebot?hl=ja
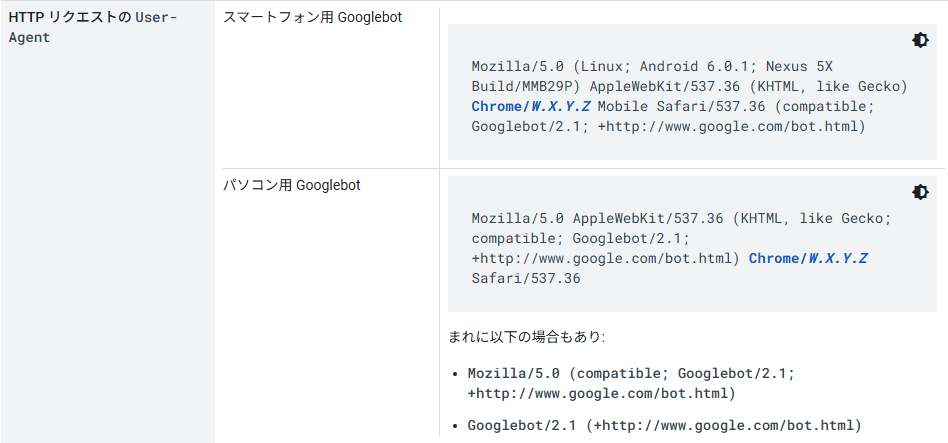
スマホ用とPC用で別のGooglebotが存在
Googlebotは、スマホ用とPC用の2種類が存在する。
スマホ用とPC用のどちらがアクセスしたかについては、HTTPリクエストのUser-Agent名を確認することで判別できる。
出典:Google の一般的なクローラーの一覧|Google検索セントラル
https://developers.google.com/search/docs/crawling-indexing/google-common-crawlers?hl=ja
ただし、2024年6月3日、Google検索セントラルブログにて「パソコン用Googlebotによるクロールの終了」が発表された。
当ブログでは、2024年7月5日以降、スマートフォン用のGooglebotのみでWebサイトをクロール、インデックス登録すると記載されている。
参考:パソコン用 Googlebot によるクロールの終了|Google検索セントラル
https://developers.google.com/search/blog/2024/06/mobile-indexing-vlast-final-final.doc?hl=ja
つまり、パソコンでは閲覧できても、スマートフォンで閲覧できないサイトはインデックスされず、検索結果にも表示されない。念のため、覚えておこう。
画像専用のGooglebotも
近年はテキストに紐づく画像も検索結果に表示される。
画像については、画像専用のGooglebotが用意されていて、主にHTML内の<img> 要素の src 属性で画像を検出してインデックス登録される。
ちなみに、CSSで読み込む画像はインデックス登録の対象にならない。
参考:Google 画像検索SEOベストプラクティス|Google検索セントラル
https://developers.google.com/search/docs/appearance/google-images?hl=ja#use-semantic-markup-for-images
クローラーを呼び込むフェッチャー
クローラーとセットで覚えておきたい機能が「フェッチャー」だ。
フェッチャーとは、文字通りコンテンツにクローラーをフェッチ(呼び寄せる)ための機能だ。
Google Search Consoleの主要機能であり、かつては「Fetch as Google」として親しまれていたが、2019年からは「URL検査ツール」の中に統合されている。
URL検査ツールを使用すれば、新たなコンテンツをアップロードしたときや記事の更新・リライト後にクロールをリクエストしたり、インデックスされているかどうかを確認したりすることができる。
1.2.インデックス登録(インデクサ)
クロールされたコンテンツは、HTMLデータとして整理され、解析・データベース化が行われる。
この処理がインデックス登録であり、インデックス登録を行う機能をインデクサと呼ぶ。
ちなみにGoogle検索の場合は、Googlebotがクロールとインデックス登録を行っているため、厳密にいえば「クローラー兼インデクサ」が動いている。
よってGooglebotは「検索順位の仕組みの本体」といってよいだろう。
インデックス登録されるための最低限の技術要件
インデックス登録されるための要件は以下のように公開されている。
要件1:Googlebotがブロックされていないこと
Googlebotのアクセスは、robots.txt内に規定の構文(disallow構文)を記載することでブロックできる。
disallow構文が使用されているページに対してはクロール自体が行われないのでインデックス登録されない。
また、非公開ページやパスワードによるログインが必要なページもインデックス登録の対象外だ。
要件2:ページが機能していること
ページが機能していることとは、HTTPステータスコードが「200(success)」状態になっているページだ。
基本的に200のみをインデックス登録の対象とするため、「URL検査ツール」などでページの状態をチェックしておこう。
参考:URL 検査ツール|Search Console ヘルプ
https://support.google.com/webmasters/answer/9012289?hl=ja
要件3:インデックス登録可能なコンテンツが含まれること
インデックス登録可能なコンテンツであるかのチェックも行われる。
「Google検索でサポートされたファイル形式」「スパムポリシーに違反していない」という2つのチェックをクリアすると、晴れてインデックス登録が行われる。
サポートされたファイル形式と、スパムポリシーについては、下記のリンクで詳しく解説されている。
参考:
Google によるインデックス登録が可能なファイル形式 | Google 検索セントラル
https://developers.google.com/search/docs/crawling-indexing/indexable-file-types?hl=ja
Google ウェブ検索のスパムに関するポリシー|Google 検索セントラル
https://developers.google.com/search/docs/essentials/spam-policies?hl=ja
1.3.検索結果への表示
クロールとインデックス登録が完了した後は、いよいよ検索結果の表示作業が行われる。
具体的には、検索ユーザーが入力したキーワードと、インデックスされたコンテンツをマッチングし、さまざまなランキングアルゴリズムによって表示順位を決定する。
ユーザーが特定のキーワードを入力すると、インデックス登録されたデータの中から関連性と品質が高いコンテンツが表示されるというわけだ。
コンテンツ以外の要素も影響する
検索結果はデバイスの種類や国、言語、所在地なども考慮されるため、純粋にコンテンツの中身だけで順位が決定しているわけではない。
上位1~5位程度は不変であることが多いが、1ページ目下位や2ページ目以降はコンテンツ以外の要素が影響しやすい。
つまり、検索ユーザーの状況(物理的な位置や使用言語、デバイスの種類など)によって異なるわけだ。
テキストに付随した画像検索について
Googleの検索結果には、テキスト検索であっても関連画像が表示される。
この画像もテキストと同様に関連性や品質のチェックが行われる。
主に、以下のような内容が考慮される。
- HTML要素で画像を埋め込む(<img>要素のsrc属性を使用する)
- 画像サイトマップを送信する
- レスポンシブ画像を使用する
- 速度と画質を最適化する
- 代替テキストを使用する
Googleの公式ページでも、画像の検索結果への表示について、ベストプラクティスが公開されているため、ぜひチェックしてみてほしい。
参考:Google画像検索SEOベストプラクティス|Google検索セントラル
https://developers.google.com/search/docs/appearance/google-images?hl=ja
2.Google検索順位決定における重要な指標
次に、Googoleの検索順位決定の仕組みの核ともいえる「ランキングアルゴリズム」と「主要な評価指標」について理解を深めておこう。
2.1主要なランキングアルゴリズム一覧
Googleの検索順位決定の仕組みにおいて、「ランキングアルゴリズム」は大きな役割を果たす。
下記の図は、現時点で公開されているランキングアルゴリズムの中で、特に重要なものをまとめたものだ。

特に注目すべきは「オリジナルコンテンツシステム」と、「レビューシステム」だろう。
独自性や第三者からの正当な評価など、ユーザーにとって有益な情報を表示するためのアルゴリズムが実装されている。
「一般に公開されている情報を整理して伝える」だけでは、順位を上げることが難しい時代になったと言えるだろう。
2.2.重要な評価指標
ランキングアルゴリズムには200個以上の指標があると言われるが、その内容はほとんどが非公開だ。
またアルゴリズムは頻繁に変化するため、アルゴリズムの詳細を追い続けることは現実的な対策になり得ない。
したがって、普遍的な指標を意識した対策がおすすめだ。
例えば下記のような指標だ。

どれも当たり前のように見えるかもしれないが、常に実践し続けるには相応の労力が必要だ。
例えば、ユーザビリティを高めるためのCore Web Vitalsでは、「短時間でスムーズに必要な情報を視認できる」ことが求められる。
コンテンツの表示速度やサーバーの応答速度など、技術的な要件への対策が必要だ。
そのほかにもドメインパワーの強化、外部評価の獲得など、コンテンツの品質以外の面でも気を配るべき点は多い。
3.Google検索順位の仕組みから炙りだす上位表示の施策
最後に、これまでの内容を踏まえたうえで、「検索順位を上げるための施策」をまとめた。
施策1.キーワード→ニーズ把握→コンテンツへの反映への精度向上
Googleの検索順位決定の仕組みは、「コンテンツがユーザーニーズに対して強い関連性を持つか」という判断から始まる。
つまり、ニーズをキャッチしたコンテンツでなければ、評価の対象にすらならない。
コンテンツの制作側としては、まず「狙うキーワード」を決め、キーワードに込められたニーズを把握し、コンテンツに反映していくという作業が求められる。
ニーズの把握については、「顕在ニーズ」と「潜在ニーズ」の2点から攻めよう。
顕在ニーズとは「当事者が自覚していて、他社にも認識できるニーズ」だ。
一方、潜在ニーズとは、「当事者が自覚していない、表面化していないニーズ」と言える。
潜在ニーズまでを踏まえたコンテンツであれば、検索ユーザーが自覚していない「本当に解決すべき課題」や「別の解決方法」を提示できる。
こうした情報を含むコンテンツは高評価の対象になりやすい。
また、潜在ニーズの把握では、業界や業務に対する深い知識や専門性、ペルソナの把握などが必要だ。
特にペルソナの把握は、潜在ニーズを高精度に推測するために欠かせない作業だ。
さらにペルソナがどのように思考し、行動するかを可視化したカスタマージャーニーも作成してみよう。
ペルソナの思考や欲求をカスタマージャーニーとして可視化できれば、コンテンツに盛り込むべき内容がより具体的になる。
施策2.信頼性、権威性とともに「独自性」も意識
E-E-A-Tで重視される「信頼性」や「権威性」は既存の事実やデータを活用することである程度は充足できる。
しかし、これのみでは順位を上げることが難しい場合もあるだろう。
攻略難易度が高いキーワードでは、上位コンテンツの大半が信頼性や権威性を担保しているからだ。
そこで「独自性」にも注目していこう。
ここで言う独自性とは、「既存の事実やデータから思考し、ユーザーにとって有益な”新たな選択肢”を提示すること」だ。
難易度が高めだが、「一般論はAだが、自社としてはBという選択肢もある」という形式であれば評価対象となる傾向がある。
ランキングアルゴリズムの解説にもあるように、独自性が評価されると単に正確な情報をまとめたページよりも上位に表示されやすくなる。
施策3.サイト全体の評価向上に取り組む
最新のGoogoleアルゴリズムのアップデート(2024年9月完了)では、小規模サイトも評価されるような変化があった。
しかし、2024年10月時点では、まだまだドメインに対する評価の影響が大きい。
特にBtoBに属するキーワードでは、権威性や知名度の高いドメインが上位を独占しがちだ。
そこで、サイト全体の評価向上、つまりドメインレートの向上にも取り組んでいこう。
ドメインレートは「運営時間×高品質なコンテンツの数」の影響を受けやすい。
質の高いコンテンツを制作することはもちろんだが、「一か月で最低10本」など、コンテンツをコンスタントにアップすることも意識したい。
また、近年はユーザビリティに関する施策も重要だ。
Core Web Vitalsの充足をはじめ、「有益な情報に、より少ない時間と手間でたどり着ける」ようなサイト作りを心がけよう。
コンテンツをカテゴリごとに分類したり、レコメンド表示を強化したりと、ユーザビリティに関する改善案はいくつもあるはずだ。
施策4.事業とコンテンツの密接度を意識する
BtoBに属するキーワードでは、「事業と関連性の高いコンテンツ」が順位を上げやすい。
例えば「CRMとは」というキーワードに対してA社とB社がコンテンツをアップしたとしよう。
A社はCRMベンダー、B社は食品業界のメーカーだ。
この場合、コンテンツの情報量や質がほぼ同一であれば、A社のコンテンツが評価されやすくなる。
コア事業と関連性の高いコンテンツは、権威性・専門性・信頼性のいずれも高く評価されるからだ。
この原理を理解すると、キーワードボリュームだけに縛られない戦略が見えてくる。
「自社のコア事業と関連性が高いキーワード」を優先することで、検索順位の上昇を狙っていこう。
4.まとめ
本記事では、Googleの検索順位が決定する仕組みや対策について解説してきた。
Googleの検索順位決定は、「クロール」「インデックス登録」「検索結果への表示」という3工程で行われる。
ランキングアルゴリズムの大枠は公開されているが、具体的なロジックや指標の大半は非公開だ。
2024年時点では「コンテンツの品質」を高める努力とともに、技術的要件にも目を背けず取り組み、サイト全体の評価を高めていくことが上位表示への近道だと言える。
弊社では、SEOの本質を理解した記事制作代行やオウンドメディア運用を支援しているため、お困りの際はぜひお気軽にご相談いただきたい。
アイティベルの記事制作代行・SEO対策サービスはこちらから↓





